
Documenting and sharing lessons learned training the Hebrew version of the Whisper Large v3 Turbo model
TL;DR
We took to the task of fine-tuning OpenAI’s Whisper v3 Turbo model.
Our initial failures — and subsequent discoveries — prompted a set of changes to the current known methods for fine-tuning Whisper.
In this article we share our findings, as well as a complete recipe (code) for training Whisper’s turbo version successfully.
While we have not tested it on other Whisper variants, we believe this recipe is recommended for them as well.
About The ivrit.ai Project
Ivrit.ai is a crowdsourced project that aims to collect data and train Hebrew language AI models, with a focus on audio, speech, and Automatic Speech Recognition (ASR). The project is operated by volunteers and relies on contributions of content, effort and resources from the community. The goal of ivrit.ai is to make all datasets and models freely available.
Previous Fine Tuning of Whisper Large v2
At ivrit.ai, we believe it is essential to train a model on the collected dataset. This approach allows us to demonstrate the value of the dataset and offer the community a practical model for a prevalent and significant issue. Having a real task also pushes for constant growth and improvement of the dataset, as well as showcases the project’s value to the hundreds crowd-sourcing volunteers driving the project.
Automatic Speech Recognition (ASR) is such a problem and the open sourcing of the Whisper model provided an opportunity to relatively easily fine tune an ASR model and make it available.
Prior to working on the Turbo version of the Whisper model, the ivrit.ai project had experience training the Whisper Large V2 model using approximately 200 hours of volunteer-transcribed audio and about 90 hours of professionally transcribed audio from a private contributor.
The training was done for less than 2 epochs. We have seen performance degrade later into the second epoch, but unfortunately did not document the training session properly at the time.
Although the resulting model achieved a state-of-the-art word error rate (WER) score, it exhibited some artifacts, notably coarse speech segmentation and hallucinations.
This coarse segmentation negatively impacted the model’s ability to produce well segmented subtitles and required post processing using tools like stable whisper.
We also got complaints about hallucinations when using the model. Hallucinations within Whisper are not unique to the Hebrew model we trained, but we now believe these phenomena are somewhat related to the above segmentation artifact.
The above has to do with how Whisper inference handles Long-Form audio (Longer than 30 second audio inputs) which I will touch on in the next sections.
Key takeaways from the previous Whisper Large v2 training:
- The dataset makes a difference — WER decrease of %20-%30 was observed over the base multilingual model
- Whisper “time stamping” ability was degraded (more on that later)
- Potentially an increase in Hallucinations
Failing to Fine Tune Whisper Turbo
Clearly when the Turbo version of the model was announced — we got excited by the opportunity to reach a broader audience and use-cases with lower requirements for hardware and a faster inference time.
Our initial attempt to fine-tune Whisper Large Turbo didn’t go as expected. We trained it on the same dataset we had previously used for the Large model, assuming that would work just as well. It didn’t. Instead, the Turbo model exhibited a strange broken pattern like this:
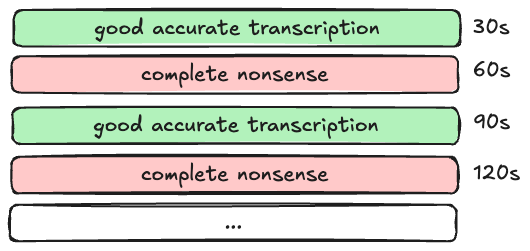
Clearly, something was off in between 30s slices — after deeper debugging we saw that:
- The model produces “timestamp token” in a very coarse and inaccurate way
- The model chokes on previous text
Both of those aspects of the model transcription process are related to long-form transcription and you might want to dive deeper into them. I have provided a more detailed description of this mechanism on this technical article.
The TL;DR is that the model learned Hebrew, and worked pretty well on short 30s audio slices, But forgot how to produce and consume the required “hints” to facilitate the long-form transcription which spans audio longer than 30 seconds. A way to visualize this:
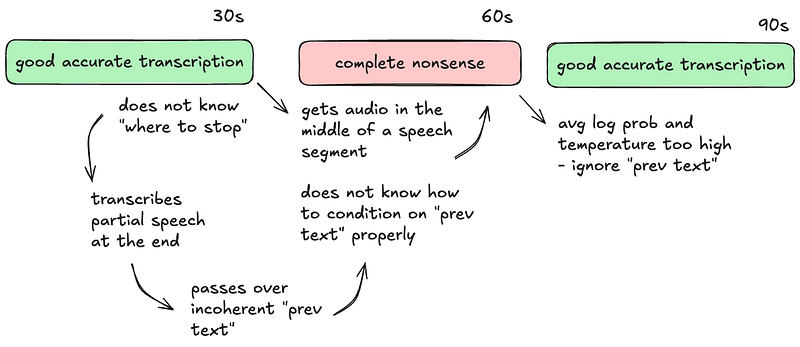
Once we saw that, we picked up on clues both on the Whisper paper and other more obscure sources and GH Issues that this indeed could result from continued training of the model, if the training dataset did not present timestamps and previous text to some extent. It is a form of Catastrophic Forgetting.
Given these findings, we realized we needed to rethink our approach. To mitigate catastrophic forgetting and improve performance, we decided to:
- Adapt our datasets to include properly timestamped labels for a significant portion of the training set.
- Generate additional datasets with correctly formatted timestamps alongside text.
- Provide previous text context to some of the training samples.
Rethinking Our Dataset Structure
Back to our basic goal, we want to amplify the model’s ability to understand and output Hebrew. But, at the same time we want to ensure it learns to do that within the same modus operandi. Especially given the reliance of most common inference engines on the Timestamp Tokens and Previous Text conditioning when processing long-form audio.
The model, then, should see some distribution of the following example buckets:
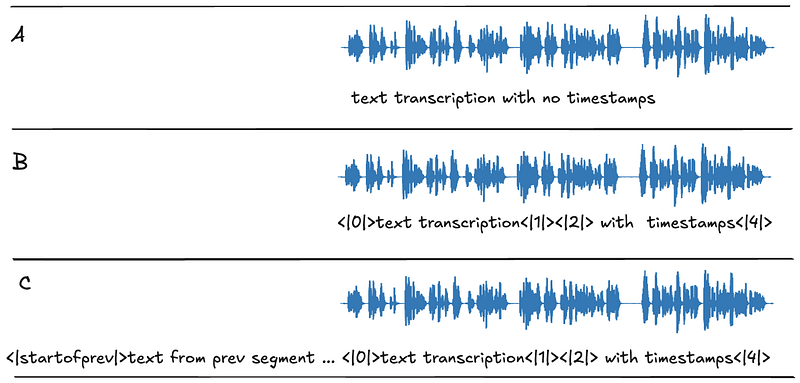
Note — Because we prioritize long-form transcription, we do not bother showing an example of previous text without timestamps — Long-form always has timestamps.
If we wanted to leverage “previous text” for conditioning on arbitrary context without long-form involved we might choose to construct such examples as well.
Bucket A is simple, this is the dataset we had already used. Buckets B and C were much harder for us to create due to how we initially generated our dataset. The source audio was pre-segmented and volunteers transcribed pieces of short audio. This produced something like this:

That means transcribed audio slices are:
- Short, averaging 5 seconds
- Are not internally segmented — too short for that
- Are not consecutive
This means we cannot produce buckets B and C from it. We made a decision to change dataset construction in the future, but here and now we still had a problem.
Luckily we had another internal dataset which was ~100 hours of professionally captioned audio sources. The text was not verbatim, and timing was not accurate — since it served as audio captions, but this was a much better starting point:

This allowed us to reverse the long form processing, in a sense — and produce a dataset which has mostly 30s audio slices, with timestamps for internal segments and previous text. Hopefully we will soon release the data pipeline code that performs the above. Until then, here are the general processing steps:
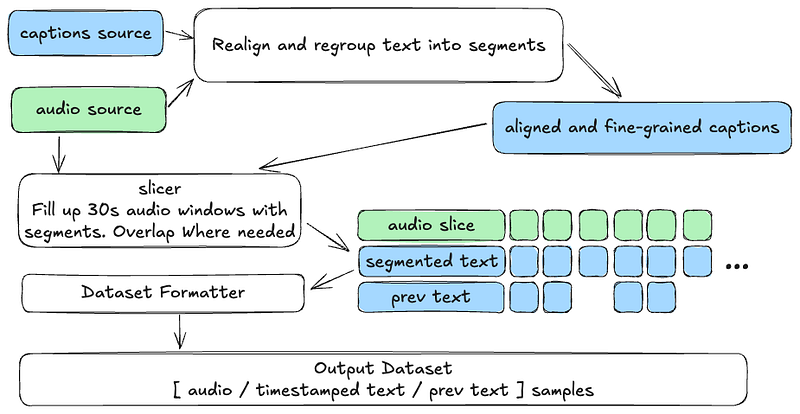
The steps are:
- Realign and regroup — this is optional, the goal of this step is to improve the segment timing and increase the granularity — which will help the model with downstream precision. We rely on Stable Whisper’s great API to do that on top of the built-in faster-whisper
align()functionality. (We used Whisper medium).
– As a side note — the alignment approach mentioned above was described on OpenAI’s notebook here and since was implemented and improved by some of the inference engines. Anyway it’s very interesting to read and follow how it’s done. - Slicer — will try and capture the way long-form transcription is done, overlapping windows if speech overflows them, and producing internal segmentation of windows.
– The slicer also captures previous text when the audio windows are consecutive. - The formatter produces whisper specific time stamped text and previous text alongside the properly transcoded audio sample.
The final dataset used for training breaks down as follows:
- ~295 hours of audio — text samples — ~5sec avg. audio length
- ~100 hours of audio — time stamped text samples — ~27s avg. audio length
– 100% with timestamps — Of which 50% includes previous text
Adapting the training code
With the above changes to the dataset, some modification to training code was needed.
Preprocessing Timestamps and Previous Text
First, we have a preprocessing step that take the Dataset samples and:
- Potentially augment the audio with random shifting in time (We did not use that eventually in our training runs)
- Prepare the audio features — Use the processor to convert raw 16khz mono audio to Mel Spec features.
- Randomly decide to include or exclude timestamps in text (we had this “always on” when timestamps are available)
- Randomly decide to include or exclude previous text if available (%50 probability)
- The above two decisions determine how to form the labels for training
We followed the general approach the distill-whisper project took creating the above.
I am not going into finer-details here, the code is available for anyone who wants to dive deeper. There is also a form of dataset audio lossless compression taking place which could be of interest (Look for DatasetPreparator).
Important, If you build your training set — it is important to get acquainted with the different token patterns expected and how the labels are structured. Good places to start are the Whisper paper, and the implementation in OpenAI’s original whisper repo. But plenty of online documentation is otherwise available.
During training the data is further processed by the Data Collator which would then:
- Derive “decoder input ids” from the labels (See below)
- Mask the label parts that should not contribute to the loss:
– The “previous text” and it’s prefix token<|startofprev|>
– The “Start of transcript” token<|startoftranscript|>
The code for our data collator is also available as part of our training code .(Look for DataCollatorSpeechSeq2SeqWithPadding)
There are a couple topics I want to spell out here, since I feel they are confusing and not intuitive.
Data Collator producing the “decoder input ids”
During training, the sample’s attribute decoder_input_ids is used to prompt the Whisper decoder for the generation of tokens. This forms the input that should produce a decoder output being compared to the provided labels for loss calculation.
Commonly, during training you derive the decoder input ids from the labels, since the generative cycle produces each label token from the previous decoder input token — they are basically the same thing shifted 1 place.
Here is perhaps a very simplified mental model to work against
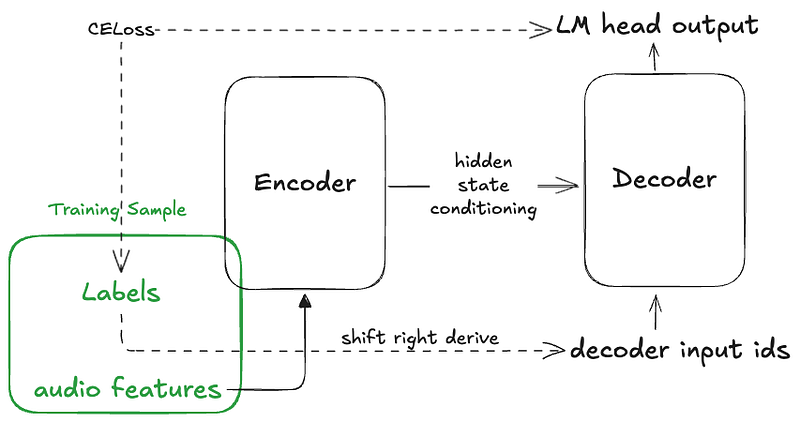
If you provide a training sample with only “labels” — The HuggingFace Whisper model will derive the decoder input ids in a way which would not work for us. It will basically “shift right” the labels to produce the decoder input ids. Here is how it looks:
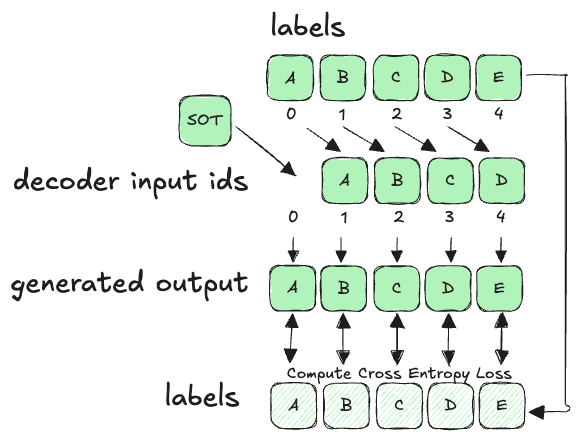
Since it shifts all tokens to the right — it chops of the last one and prepends the decoder_start_token_id for the tokenizer — for Whisper this is <|startoftranscript|> (SOT).
This could only work if you know in advance to produce labels which omit the first SOT token but still produce the “task”, “language” and potentially “no timestamps” tokens before the text.
This is abnormal, since when you call the Whisper tokenizer to produce label token ids from text, it will by default add all “prefix” tokens — and you need to know, somehow, to remove that first SOT token to compensate.
In this popular HF blog post about fine tuning Whisper this issue is addressed by explaining why the SOT (referred as BOS there) is removed.
But, if you want to add “prev text” to your sample labels — this would no longer work. SOT token is in the middle of the “labels” and the decode input ids would turn out plainly wrong.
To work around that, your Data Collator can produce explicit decode input ids to condition on, and the internal default derivation will be skipped — and this is what Distil-Whisper ended up doing, and recommended by the maintainers in some GH Issues.
Since we also want to mask the labels such that loss is not calculated from the prev text and SOT token — we end up with this in the data collator:
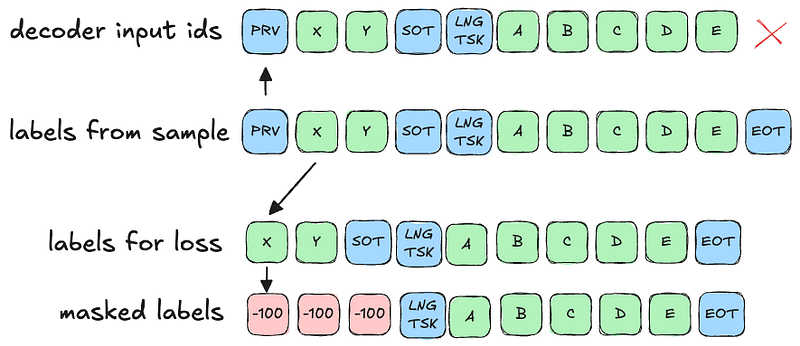
This pre-aligns labels to match against generation outputs (labels are shifted left relative to decoder input ids) and properly mask prev text and SOT.
As a side note, the aforementioned mechanism of internal “shift right of labels” (which you need to work around) was inherited from BART where it made sense since there was only one generation “prefix” token. For Whisper, this is no longer true.
Additionally, The assumption that “labels” are pre aligned with “decoder outputs” is not common across other decoder-containing models. And indeed HF’s general loss function today assumes a shift is required to align them before CELoss is calculated. I wanted to address this in this GH issue and hopefully a logical coherent code would be contributed to address this.
About Balancing our Dataset
As you recall from above — our training dataset consisted of about 295 hours of short samples with no timestamps and 100 hours of long segments with timestamps and prev text.
It is unclear to us what was the exact distribution of data used in training the Large v3 Turbo model by OpenAI. But it seems like this was not a small percentage, for example the Whisper paper suggested 50% of the samples also included “prev text”.
Distill Whispers default in the code point towards 20% with timestamps and 20% with prev with independent random choices.
Since the timestamp-aware portion of our dataset was of high quality transcription we decided to use all of it without removing timestamps, and half of it removing prev text.
This leads to about 100/400 hours with timestamps (%25) and 50/400 with prev and timestamps (%12).
Token Density Balancing and a Gotcha
Token density was also imbalanced — Since the 295 hours dataset (DS-1) included 203K samples averaging 41 tokens per sample and the 100 hours dataset (DS-2) included 13K samples averaging 226 tokens per sample.
We sampled thus from DS-1 and DS-2 in 5:1 ratio — such that each training batch would include more or less the same token amount from each dataset. Of course this means within each epoch we oversampled DS-2 which did not seem to hurt learning progress but potentially converged slower than it could. We intend to challenge that in future training efforts.
Since we had relatively modest compute resources — we opted to use Gradient Accumulation Steps to produce a 32-sample batch, and this led us down a small rabbit hole of a bug in the HF Trainer which was not fixed for Whisper.
More details about this bug in this blog post and this issue we opened to help address this.
In essence, the imbalance in token count should not have had any impact on training loss contribution, but the aforementioned bug caused smaller samples to have a larger impact on the loss gradient due to how the loss ws aggregated across “gpu batches” to form the “global batch” loss.
Training Session Description
The training was done on a modest single RTX 4090 (24GB VRAM) GPU machine, almost maxing out the memory capacity with a GPU batch size of 2 and gradient accumulation. Steps of 16 to form a global batch of 32. We used a Learning Rate of 1e-5 with a warmup of 800 steps (Around 25K samples, representing about %10 epoch duration) and linear decay over 5 epochs.
We ended up stopping the training after about 2 epochs due to a problem with the machine, but we intended on stopping even earlier anyway since the Eval loss seemed to plateau. This is not ideal, but we intended on perusing future training runs to further investigate the correct training duration.
Training ran for 49 hours, and we picked the latest checkpoint before the technical problem stopped the training without leveraging with other checkpoints or runs although this is something we intend to approach in the future.
75% of the datasets used for training is publicly available under the ivrit.ai HF repo here. The other important 25% percent, which included the timestamped data and prev text is currently unreleasable due to licensing constraints. We are working on creating an alternative, openly available dataset which could also serve the same “time stamping/prev-text grounding” purpose.
Final Thoughts
Fine Tuning Whisper could shift the distribution such that the per-segment WER improves, but the long-form WER degrades.
Depending on the dataset size used, distribution divergence from original training set and amount of training, Whisper Turbo is apparently more prone to Catastrophic Forgetting.
If Whisper forget how to produce Timestamps and condition on previous text, long from transcription breaks since inference engine rely on the above to accomplish this task.
I speculate that Whisper Turbo, given the unbalanced Encoder-Decoder sides would tend to forget more on the Decoder side which has the task of predicting language and timestamp tokens from the audio features and previous text.
The importance then, of training Whisper Turbo on examples that include proper segmentation, time stamping and previous text is higher compared to the Large model — from empirical standpoint, and with the above reasoning the back that assumption.
References and Acknowledgments
We at ivrit.ai can be found here, on HuggingFace and Github.
Two very helpful and knowledgable individuals are a never ending source for advice and insights on this topic— OpenAI’s Jong Wook Kim and MistralAI’s Sanchit Gandhi — Thousand thanks.
The great work on Stable Whisper (Stable TS) is priceless if you wish to get the best out of Whisper — Thank you Jian.
I would love to hear your thoughts and comments.
Leave a Reply